为什么 OpenClaw 消耗 Token 这么快?
这篇文章的第一部分回答一个最基础、但也最关键的问题:
每次交互,OpenClaw 到底向模型发送了什么?
当我们说“上下文很大、token 消耗很快”,本质上是在说:每一次调用模型 API 时,OpenClaw 会把一段“完整输入”发送给模型,这段输入往往远超过用户的当前一句话。
下面是这段输入的组成和来源。
1. System Prompt(系统提示词)
系统提示词是 OpenClaw 每次调用模型都会带上的“基础说明书”。它包含了多段固定或半固定内容,核心目的是让模型知道它是什么、有哪些工具、在哪个工作目录、如何处理记忆和渠道消息等。
System prompt 是一个“大盒子”,内部包含以下子块:
- Tooling 段:列出工具清单以及简要说明。
- Safety 段:基础安全与行为约束。
- Skills 段:技能目录提示(可很长,随技能数量增长)。
- Memory 段:记忆检索规范(告诉模型先搜索 MEMORY.md 等)。
- Documentation 段:本地文档路径提示。
- Workspace 段:当前工作目录 + 备注。
- Project Context 段:注入的上下文文件内容(通常是最大头)。
- Messaging/Voice/Reply Tags/Sandbox/Runtime 等辅助段。
下面的 2~4 小节之所以单独展开,是为了突出这些子块在 token 体积上的“贡献度”,而不是把它们当作 system prompt 之外的独立部分。
System prompt 的构建逻辑集中在:
src/agents/pi-embedded-runner/run/attempt.tssrc/agents/pi-embedded-runner/system-prompt.tssrc/agents/system-prompt.ts
2. Project Context(项目上下文注入)
这是 token 消耗最明显的部分之一。OpenClaw 会在每次运行前读取一组 workspace 的“引导文件”,再将它们原文注入到 system prompt 中。
默认会读取的文件包括:
AGENTS.mdSOUL.mdTOOLS.mdIDENTITY.mdUSER.mdHEARTBEAT.mdBOOTSTRAP.mdMEMORY.md或memory.md
这些文件会被逐个裁剪(单文件上限默认 20,000 chars),然后以如下形式插入:
# Project Context
## BOOTSTRAP.md
<内容>
逻辑位于:
src/agents/workspace.ts(读取文件集合)src/agents/bootstrap-files.ts(组装注入)src/agents/pi-embedded-helpers/bootstrap.ts(裁剪)src/agents/system-prompt.ts(最终注入)
3. Skills 列表(技能清单)
如果开启了 skills,OpenClaw 会把全部 skills 编成一个目录段落,注入到 system prompt。这个列表会随技能数量和描述长度线性增长。
它不是“工具”,而是“工作流程说明”,模型会根据提示去读 SKILL.md。
相关逻辑:
src/agents/skills/workspace.tssrc/agents/system-prompt.ts
4. Tools 定义(工具清单 + schema)
模型真正能调用的工具列表(如 read、exec、message)会被注入到 system prompt 中,同时工具参数 schema 也会被传入模型。这部分通常不会在 prompt 里完整展示,但仍会占用输入 token。
相关逻辑:
src/agents/pi-tools.tssrc/agents/system-prompt.ts
5. 历史对话 + 工具结果
除了 system prompt,OpenClaw 还会把 session 中的历史消息、工具调用结果一起发送给模型。这些历史会不断累积,直到触发 compaction 或 memory flush。
相关逻辑:
src/agents/pi-embedded-runner/run/attempt.ts(加载历史)src/agents/pi-embedded-runner/compact.ts(压缩)
6. 当前用户输入
最后才是用户的这一条消息,它会和上面所有内容一起构成“本次 API 调用的完整输入”。
总结:一次交互实际上不是“只发你这一句话”。
OpenClaw 每次调用模型,会发送:
- system prompt(很长)
- project context(很长)
- skills 列表(可很长)
- 工具 schema(可很长)
- 历史对话与工具结果(会不断增长)
- 当前用户消息
这就是为什么 token 会增长得很快。
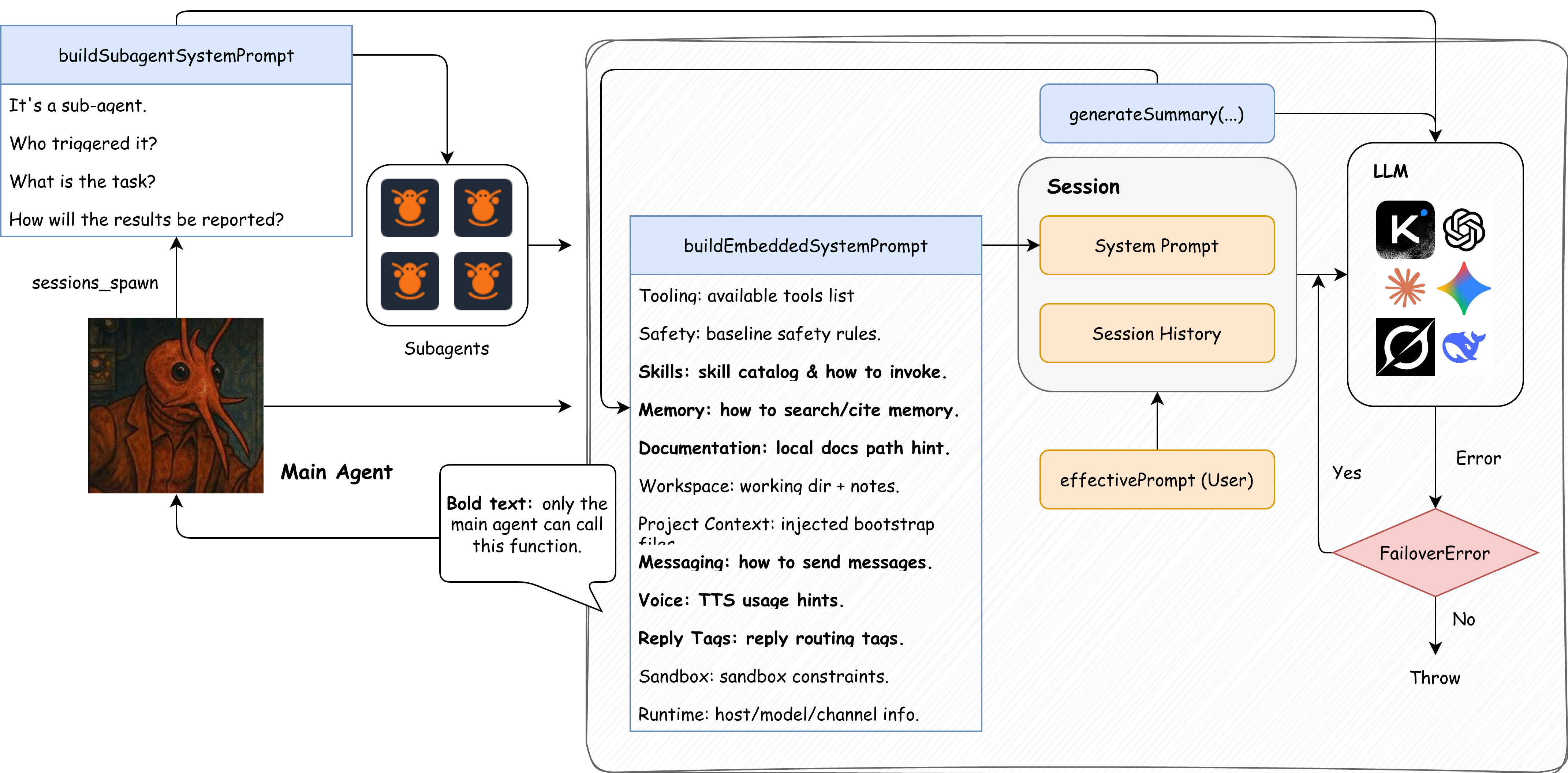
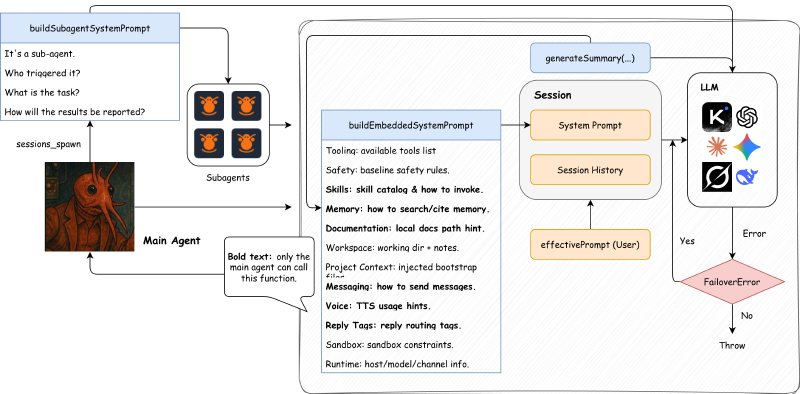
图:一次请求中 system prompt、session history、用户输入与子 agent/fallback/compaction 的关系。
代码佐证:系统提示词的“总装配口”
以下是 src/agents/pi-embedded-runner/run/attempt.ts 中的关键片段,能直观看到哪些内容被打包进 system prompt(已做精简):
// src/agents/pi-embedded-runner/run/attempt.ts
const appendPrompt = buildEmbeddedSystemPrompt({
skillsPrompt, // Skills 列表
contextFiles, // Project Context(BOOTSTRAP 等)
tools, // Tool 列表 + schema
docsPath, // 文档提示
runtimeInfo, // 运行环境信息
workspaceNotes, // workspace 提示
sandboxInfo, // 沙箱信息
modelAliasLines, // 模型别名
// ... 还有更多辅助信息
});
一次请求可能触发多轮 API:工具调用链
一个“用户请求”不一定只调用一次模型 API。最常见的原因是 工具调用链:
- 模型看到工具列表后,先发起 tool call(如
read/exec)。 - OpenClaw 执行工具,产出 tool result。
- 工具结果被写回 session(作为工具消息)。
- 模型继续生成,必要时再发起下一次 tool call。
这意味着一次用户输入可能产生多轮模型交互,从而更快消耗 token。
对应代码入口(精简路径):
- 工具定义:
src/agents/pi-tools.ts - session 创建 + tools 注入:
src/agents/pi-embedded-runner/run/attempt.ts - 订阅工具事件:
src/agents/pi-embedded-subscribe.ts - 工具执行生命周期处理:
src/agents/pi-embedded-subscribe.handlers.tools.ts
失败重试 / fallback:模型回退与重试如何发生
OpenClaw 并不是“遇错就算了”。当模型调用失败(超时、限流、鉴权等),系统会尝试模型回退,继续用候选模型列表中的下一个模型重试。
核心逻辑在 runWithModelFallback 中实现:src/agents/model-fallback.ts
它的逻辑非常清晰:
- 先根据配置生成“候选模型列表”(来自
agents.defaults.model.fallbacks或调用时传入的 override)。 - 按顺序逐个尝试调用模型。
- 只有当错误被判定为 FailoverError 才会进入下一轮回退;否则直接抛错。
这意味着,一次用户请求可能因为回退机制而触发多次 API 调用。当然,这是好事。
Compaction 与 Memory Flush:上下文快满时发生了什么
当上下文快满时,OpenClaw 可能触发两种不同的额外模型调用:
一个是 Compaction(摘要压缩),一个是 Memory Flush(记忆写入)。两者目的不同、流程也不同。
1. Compaction(摘要压缩)
目标:把历史对话“压缩成更短摘要”,释放上下文空间。
实现逻辑在:src/agents/compaction.ts
关键点:
不是一次性把全部历史发给模型
会先按 token 将历史分块,然后逐块调用模型生成摘要,再合并为一个总摘要。如果单条消息太大
会走 fallback:只摘要小消息,大消息用占位提示。
简化流程:
历史消息 → 按 token 分块 → 每块调用模型摘要 → 合并摘要
2. Memory Flush(记忆写入)
目标:在 compaction 之前,把“长期记忆”写入磁盘(memory/YYYY-MM-DD.md)。
触发逻辑在:src/auto-reply/reply/agent-runner-memory.ts
提示与默认文案在:src/auto-reply/reply/memory-flush.ts
关键点:
不是摘要历史
而是让模型整理出“值得长期保存的记忆”,写到memory/目录。这是一轮额外的模型调用
目的在于保存持久记忆,而不是压缩上下文。
子 agent / sessions_spawn:并行与分工如何导致额外调用
当任务复杂、耗时或适合并行时,主 agent 可能会调用 sessions_spawn 工具,把子任务交给子 agent 处理。这会启动一个全新的子会话,它拥有自己的 sessionKey、system prompt 和工具链路,因此会带来额外的模型调用。
核心入口在:src/agents/tools/sessions-spawn-tool.ts
简化流程如下:
- 主 agent 调用
sessions_spawn(这是一种模型的工具调用选择)。 - 系统生成
childSessionKey(agent:<id>:subagent:<uuid>)。 - 构造子 agent 的 system prompt(
buildSubagentSystemPrompt)。 - 通过
callGateway启动子 agent 的独立运行流程。 - 子 agent 完成任务后,结果回传主会话。
简单来说,就是 子 agent 是“另起一条完整会话”。因此它会显著增加整体的 API 调用次数与 token 消耗。