
This article is more of a “reflection,” documenting the development journey of nebula-pyg.
First Encounter
I must first thank the OSPP platform, which introduced me to the NebulaGraph community and to Mentor wey-gu.
Of course, there was competition for project selection. Initially, I was attracted to two projects—Kwok’s “Adding Realistic Pod Behavior Simulation Strategies for KWOK,” and the one I am currently working on: “NebulaGraph PyG Integration.”
I am the kind of person who fears competition, interviews, and presenting ideas (Honestly, I’m just not good enough. If I knew these things well enough, I should be able to talk about them with ease). Even though I really wanted to explore cloud-native development, I eventually gave up because I didn’t feel skilled enough and turned instead to PyG, which I was more familiar with.
Looking back at my email exchanges with Mentor wey-gu in April, there were seven in total—I sent five, haha. The first one went unanswered, so I followed up about ten days later and finally got a reply. To be honest, reading those emails now makes me feel like I was overly eager back then.
After we connected on X, our communication became much easier. Once I briefly shared my ideas, we prepared for our first online meeting.
This exchange was also a pretty unexpected thing, haha. Seems like I wasn’t told the exact time to join the meeting, so I just found a coffee shop and walked in, completely clueless when I went in and just as clueless when I left.
During our discussions, I discovered that the other two members working on this project with me are also highly capable. One of them, in fact, came across some relevant search results on Google during the subsequent development phase. Through his blog, I could see that he had done a lot of preparatory work beforehand.
I guess I was really lucky to have been chosen!
(Still wondering why I got selected, haha.)
Then came a long period of waiting for results. Finally—accepted!
Design
The overall design of this project draws inspiration from the remote adaptation work for PyG implemented by KUZU.
The framework remains largely consistent, with specific adaptations made to accommodate the unique characteristics of Nebulagraph.
Framework
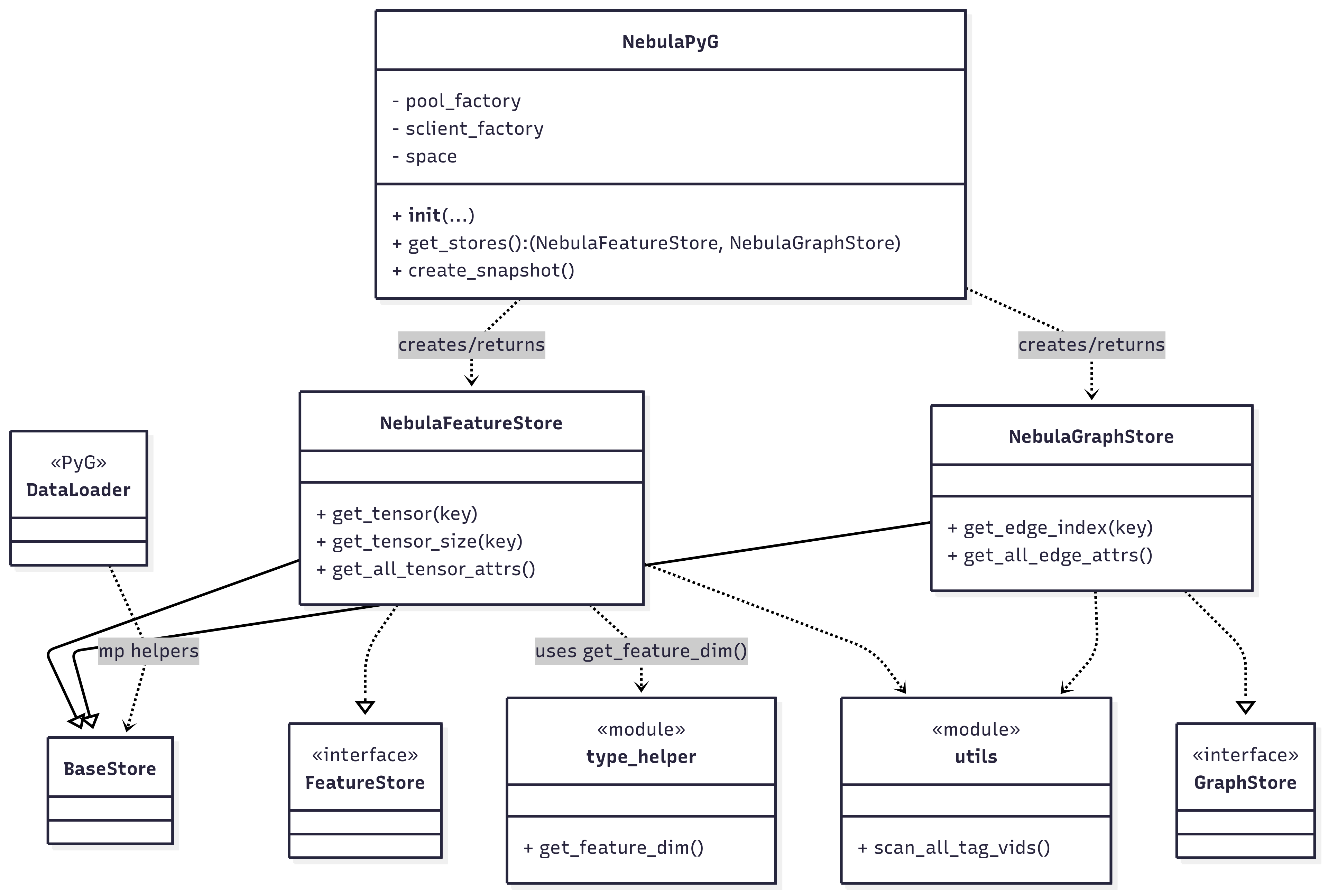
Overall, the core focus is implementing the FeatureStore and GraphStore interfaces within PyG.
At the upper layer, an additional class is created to instantiate these two interfaces, enabling the return of both instances with a single line of code—this is the current NebulaPyG class.
The NebulaPyG class also includes a dedicated method create_snapshot() to address the vid issue.
The utility classes from the FeatureStore and GraphStore interfaces have been generalized and placed in the utils.py and type_helper.py packages.
This includes tools such as get_feature_dim() for determining feature dimensions and scan_all_tag_vids() for generating global snapshots.
Additionally, a base_store class has been introduced for inheritance by FeatureStore and GraphStore, specifically addressing the multi-process issues within PyG’s DataLoader.
Below is the overall class relationship diagram.
Details
Environment
This was a major issue encountered during the development of nebula-pyg. It was the first time I realized how unfamiliar I was with the environment.
The first challenge was environment management. nebula-python uses pdm, a relatively decent package manager. Why “relatively decent”?
- pdm didn’t feel particularly convenient to me; it still has quite a few pitfalls. Its primary function is to address the dependency version consistency issues that traditional tools like
venvlack (e.g., nebula-pyg depends on package A, package A depends on package B, Traditionalvenvcan specify version A but not version B, leading to scenarios like A1 requiring B’sX.1-X.2version while A2 needsX.2-X.3. This is where pdm shines by pinning B tox.2). I haven’t fully experienced this feature yet since I’m not involved in multi-terminal collaborative development. - I find pdm’s support for torch rather mediocre. It requires manual configuration, and packages like
torch-visionindeed encountered strange installation issues. I recall this problem being fairly common—similar issues occurred when usingminicondapreviously. - After research and discussions with Mentor Wey-gu, it seems UV is poised to dominate the field (I’ll give it a try someday).
The second issue concerns Nebulagraph’s environment. Currently, the community edition of Nebulagraph’s storaged can only be accessed by Python interpreters within the same network and cannot be accessed from external networks. This necessitates installing both Nebulagraph and Nebula-pyg’s Python interpreters on the same network when using Nebula-pyg. Furthermore, Nebulagraph can only be installed on specified Linux environments.
There are two scenarios for users employing nebula-pyg:
- Using a specific Linux system with NebulaGraph installed in that environment, where the interpreter also runs locally.
- Using docker-compose to launch nebula-graph, then installing the Python interpreter on the same network for development or usage via SSH. Note: Using WSL is not highly recommended due to its severe I/O issues (as pointed out by Mentor Wey-gu, and subsequently confirmed in practice where this caused storaged corruption and file read/write problems).
Of course, method 1 is the recommended approach.
vid
Nebulagraph’s VID supports two types: FIXED_STRING(<N>) and INT64.
PyG imposes the requirement that edge_index must be in the range {0,……,num_nodes-1}.
So, is this conversion necessary? In KUZU’s implementation, this decision rests with the user—users must ensure the index meets the above requirements during data import. Looking back, delegating this responsibility to the user is a sound approach. From a purely research perspective, most datasets on the market have indexes constrained within this range.
However, for industrial-grade data, most systems employ UUIDs based on specific rules or IDs generated using the Snowflake pattern. Especially in distributed databases, auto-incrementing int types are rarely used. In such cases, the VID mapping becomes particularly essential.
When designing the mapping solution, KV-Cache was considered. Following advice from Mentor wey-gu, two key points were primarily addressed:
- Should dynamic scenarios be considered? The answer is that they are not particularly necessary. Even at industrial scale, creating a subgraph via snapshot remains extremely fast.
- How should consecutive IDs be handled when deleting tags? This is very difficult to manage within KV-Cache.
In summary, we adopted the Snapshot solution (go snapshot!) and utilized Python’s native pickle for persistence.
The pickle file generated by Snapshot contains the following components:
vid_to_idxidx_to_vidvid_to_tag: node classification informationedge_type_groups: triplet information
The first two seemingly redundant reverse designs are not redundant. Instead, the key-value pairs within the dict enable faster forward queries with a time complexity of O(1). If you were to use only vid_to_idx to look up vid by idx, the time complexity would increase to O(n).
FeatureStore’s Scanning Strategy
Around early August, I completed all tests using the basketballplayer sample dataset from the Schema Planning section of the Nebulagraph documentation. After successfully running all tests, I was thrilled and had already started planning the next steps.
The nightmare began when I decided to work on a large-scale dataset case.
I chose ogbn-products, which I considered a classic example. When I started running it, about an hour passed and nothing happened. At the time, I assumed it was a performance issue, possibly related to WSL I/O or my computer’s specs.
After returning home from a roughly seven-hour outing, I was stunned to see the progress remained unchanged. In my experience, 2,449,029 nodes shouldn’t cause such severe performance issues—it couldn’t even finish reading in seven hours.
Still skeptical about the dataset size, I switched to ogbn-arxiv.
I added breakpoint printing and discovered the data read operation performed countless iterations of scan_vertex_async. What was going on?
My initial design for get_tensor involved calling storaged’s scan_vertex_async (this interface was also in my PR to nebula-python, though it seems not yet updated) (Update: Successfully merged) on October 18th!).
This interface performs a global scan of the graph to retrieve a specified prop with a given tag from the global data. However, it lacks the capability to fetch a vertex at a specific index. My design handles this by comparing the desired index with the vertices scanned across the entire graph,
then returning the prop of the required vertex.(As we’ll see later, this turned out to be a very poor design.)
Let’s re-examine the process to pinpoint where the issue lies. When PyG uses Neighborloader, it first retrieves a list of points and loads surrounding points based on the batch_size parameter.
For example, with batch_size = 32, it fetches 32 points from the list, then retrieves the neighbors of these 32 points. These points are used as an index to call get_tensor.
In ogbn-arxiv, this amounts to roughly 600+ points. *The number of get_tensor calls is typically determined by the number of features (another pitfall I encountered handling x,y in get_tensor), the number of epochs run, and the number of batch training passes. *
Therefore, using a global scanning interface like scan_vertex_async to retrieve data from the dataset scans all 169,343 nodes each time. Comparing this to the actual requirement of just over 600 nodes reveals significant performance waste.
Now, let’s compare our work with KUZU and wey-gu’s previous contributions to nebula-dgl for DGL (I just took a closer look—I only knew this project existed before, haha):
- KUZU: KUZU is straightforward. Its
scan_vertexfunction includes anindicesparameter, allowing direct retrieval of props for a specified index (index) from storage based on the indices. - nebula-dgl: During training, DGL typically scans the entire graph to read data and generate the graph object. Subsequent operations default to slicing data on demand from the graph object’s
g.ndata/edata. This avoids frequent read/write operations like PyG. (If I’d seen this earlier, I might have explored thequeryapproach for small graphs and subgraphs.)
Regarding Solution 1, I find it extremely convenient—it only requires adding an operator to Nebulagraph’s storaged. However, this solution was rejected outright. Reflecting on it, I recall—though my memory is hazy—Mentor Wey-Gu mentioning that storaged is only suitable for full-graph scans, not for conditional queries.
After some research, first, Nebulagraph’s Storaged is based on RocksDB (PS: RocksDB is worth exploring when I have time!), which inherently supports sequential reads (iterators) and directly provides full graph traversal capabilities. Second, implementing this functionality requires handling predicate evaluation, union conditions, optimal index selection, table lookup for property retrieval, and aggregation/deduping/sorting. Functionally speaking, these tasks fall under the query optimizer’s responsibilities and should ultimately be handled by graphd.
Ultimately, following wey-gu’s recommendation, we opted to use ngql for the relevant operations. Wey-gu also mentioned that Nebulagraph further optimized the operations I described. Subsequent testing confirmed that when fetching 100,000 points, all data could be returned within approximately 1.2 to 1.5 seconds.
The ultimate solution is also straightforward: simply use the fetch statement to query.
Of course, there’s also the match method.
match is more powerful, capable of handling multi-hop subgraphs and other features. However, it performs less efficiently than fetch. Since we only needed to retrieve node property values based on the index and had no other functional requirements, we opted for fetch.
Handling x,y in get_tensor
This was another issue not initially considered.
As mentioned above:
The number of
get_tensorcalls is typically determined by the number of features…
This is because during training, PyG retrieves the attribute list via get_all_tensor_attrs. Based on this list, it performs a get_tensor operation for every attribute present in the list during each batch of every epoch.
For example, in ogbn-arxiv, there are feat0, feat1…feat128—128 attribute columns plus the label column.
PyG will then perform 128+1 get_tensor(attr=TensorAttr(group_name=“paper”, attr_name="feat0", index=...)) operations to retrieve features/attributes.
In the previous section, I consistently encountered errors after approximately 100 training iterations, leading me to suspect an issue with the attr section. This is because PyG model training requires the presence of data.x and data.y.
However, I did not have these (data.x and data.y), only have the feat0 to feat128 columns and the label column.
The task now is to transform feat0-feat128 into data.x and the label column into data.y.
(Seeing how others handle things really teaches me a lot)
I looked at KUZU’s solution to this problem—basically, there is no solution, haha. Because it requires users to import feature data as [multidimensional tensor float types](https://blog.kuzudb.com/post/kuzu-pyg-remote-backend/#:~:text=x%3A%20128%2Ddimensional%20node%20features%20(so%20128%2Dsize%20float%20tensors) (which should be vectors).
So the solution to this problem is something we have to figure out ourselves.
Since NebulaGraph does not support vectors, and worse still, does not support composite data types, such as Lists, Sets, or Maps, when storing data, we must continue to store it as 128-column feature vectors like feat0-feat128, just as before.
The first question is whether the composition of this feature and the conversion of the label should be handled by Nebula-PyG or by the user themselves.
Let’s tackle the simpler one first: the label. I believe this is not a particularly difficult problem to solve within nebula-pyg.
To address this, I introduced the constant Y_CANDIDATES, which defaults to the labels label, y, target, and category for the data.y label.
During the reading process, the feature values for these labels can be directly converted to data.y.
Next comes the processing of features. Here again, the question is whether to leave it to the user or let nebula-pyg handle it. The main considerations are as follows:
- In my experience, features that have undergone special processing often require extensive ablation experiments. During concatenation, users only need to remove unnecessary columns from
data.x = [data.feat0,……,data.feat128]. - Requiring users to manually concatenate features—essentially adding a couple lines of code—would significantly degrade the user experience.
Since both approaches have merits, why not have both?
We need to distinguish between modes. I’ve introduced the expose parameter with two modes: x and feats, with x as the default. When users need to handle features themselves, they can use feats.
In x mode, the primary processing involves: when get_all_tensor_attrs is called, it generates a dictionary containing all features (dict), but only returns x and y. Upon receiving x, PyG uses it as the attr.attr_name argument for get_tensor.
get_tensor then automatically identifies the feature, reads the aforementioned dictionary, and returns data.x containing all features in one go.
(2:26 AM, my schedule is seriously messed up. I shut down my computer 20 minutes ago, but now I’ve turned it back on to finish this in one go.)
Multi-process Handling
This section is actually quite lengthy. While working on it, I found it so worthwhile that I wrote a dedicated document solely covering this topic. For details, see Multi-process description. This blog primarily documents my thought process rather than focusing on specific implementation details.
Remember how the FeatureStore scanning strategy introduced the query parameter? Well, let me tell you—this feature caused me no end of headaches.
Introducing one issue led to three major engineering challenges: the FeatureStore scanning strategy, handling x,y in get_tensor, and the current one.
As I recall, this issue surfaced when I set num_workers to a value other than 1, causing various out-of-order responses in query’s resp.
To explain the root cause: in the code, query is executed by session (graph client or gclient). PyG’s DataLoader has a num_workers parameter that enables multi-process data reading. This makes session isolation critically important.
Unfortunately, NebulaGraph’s session is not secure. Even though nebula-python specifically implements a session_pool, it’s regrettable—yet not entirely surprising—that Mentor Wey-Gu pointed out this session_pool is also insecure. The silver lining is that I discovered this after completing my work on this part, so at least my efforts weren’t wasted. Haha.
In the original design, users only needed to initialize one gclient (connected to graphd) and one sclient (connected to storaged). All subsequent operations were performed through these two objects.
This issue didn’t surface earlier when frequent query operations weren’t involved. That’s because the previous scan of the entire graph took at least ten seconds each time, and the resp returned was identical every time. Even if the response order got scrambled, it didn’t matter.
I won’t elaborate on the specifics of the solution here—all details are documented above. I’ll briefly highlight a few noteworthy points:
- PyTorch’s
DataLoaderhas two modes: Fork and Spawn. If it were the latter, I might not have needed to write this operator at all. - The current solution uses a factory function & lazy loading approach. I’m still exploring more convenient patterns. Although I’ve written a factory function utility, I haven’t committed it yet. I feel parameter passing remains a significant challenge, and I haven’t found a good solution yet.
- No memory usage tests have been conducted. How should this be approached?
At this point, congratulations to myself 🎉 for completing nebula-pyg—a robust tool with rich functionality. At the very least, I believe it offers more features than KUZU.
Lingering Echoes
Having written this far, the technical log is complete. My mind still holds many personal reflections and subsequent entries.
My deepest gratitude to Mentor wey-gu—I really want to express where this appreciation stems from, haha.
Let me recount this chronologically. At the very beginning, I was genuinely terrified. I had no idea what kind of person Mentor wey-gu was. My only impressions were “Why hasn’t he replied to my emails yet?” and “Am I really about to stake my entire livelihood on this project?” This anxiety likely stemmed from my deep concern for the collaborative experience. I’m always eager to seek guidance and collaborate—provided I genuinely connect with the person first. I simply can’t accept working with someone I don’t know at all. If that’s the case, I’ll shut myself off completely. Maybe that’s just an INFJ thing.
After adding X for some initial communication, including an online meeting, I suddenly thought, “Wow, this person is amazing. Can I really collaborate with someone this talented?” (I was instantly intimidated).
Following iyear’s advice, I worked hard to make my presence felt: doing preliminary research for the project, contributing to issues, aiming for a few PRs when possible, and thoroughly revising my project proposal. All that effort paid off!
Until the next thing happened, I always felt this mentor was incredibly busy yet remarkably free. The freedom came from my own hesitation about whether to submit daily or weekly reports—to which Mentor Wey-gu simply shrugged, implying they were redundant. The busyness? Well, he just seemed perpetually swamped, haha.
The next step was setting up the environment. Honestly, I was mentally drained at this point—I’d been at it for over a week and still hadn’t even gotten the environment working. I had no idea how to proceed with development. But the good news was, wey-gu immediately scheduled a video call with me. Once he realized I was stuck, he first explained the Nebulagraph framework and the general direction for project development. Then, he spent nearly two hours remotely configuring my environment for me! Throughout the process, he shared tons of knowledge and techniques I hadn’t known before.
Deep down, I’ve always been wary of remote support. Whenever I reached out to iyear, the most common response was “This can’t be solved remotely.” And when I helped others, I also felt that helplessness remote support often brings. So this time, my little heart felt thoroughly warmed, haha. Afterward, I gave Hera a big shoutout.
It seems like after that, we never video chatted again. Most issues could be easily resolved through phone calls and text (turns out the first video call was actually the last one).
At the end of July, I happened to be in Shanghai for a VISA-related matter (and let me sneakily mention that Hera was also very supportive of me arranging this meal). I successfully got to have lunch with wey-gu. It wasn’t really mealtime, and honestly, I was the one eating heartily. I guess my teacher wasn’t very hungry at the time either, but he stayed and chatted with me for two hours. For me, it was incredibly rewarding. I encountered patterns I hadn’t known existed before and gained deeper insight into the open-source community. After that, I started browsing X daily, feeling that the people here are all so fascinating.
The VISA situation was genuinely frustrating. Development felt stalled for days afterward, and progress hasn’t picked up much since. My mentor offered plenty of reassurance, but one piece of advice stuck with me: roughly, that daily energy is abundant—don’t waste it on outcomes beyond your control. You can channel that energy into creating so much more!
Suddenly felt like I’d covered enough here—no need to go into every detail. Beyond that, he often shares open-source projects and tools with me, and they’re truly amazing.
Hera is such a kind-hearted and beautiful person, haha. Because of this (inner agreement), I really wanted to visit Yuhang to see Nebula’s company setup, and Hera gave me such a warm welcome!
Looking back after finishing this project, it wasn’t that big—just a few thousand lines of code. I’d even say the core code was under 2000 lines, with the rest being examples, tests, and docs. But it felt way more rewarding than writing CRUD stuff before. I gained skills in Python, Docker Compose, WSL, PDM, and more—not to mention enhanced abilities in independent thinking, discussion, solution design (something I’m genuinely proud of now), tool exploration, and a renewed curiosity about the open-source community. I even contributed a single line of code via a PR.
Let me abruptly shift gears and change the topic, haha. As this project truly nears its end, I feel a bit of disappointment, though there are definitely happy moments too! At least it’s finally wrapping up, haha (though I wonder how heavy the maintenance burden will be later). I always dread moving from one environment to another. So when a project reaches its conclusion, it means the current environment—transitioning from a non-comfort zone to a comfort zone—is about to become a new “non-comfort zone” again.
Additionally, hearing once again that the repo needs to be donated to the community brings excitement tinged with a hint of sadness. I remember when wey-gu first told me the repo would be donated to the community—I was genuinely thrilled. Wow, my repo could be accepted by the community too. But now it feels like I’ve nurtured it for two months only to see it leave. BTW, during development, I kept thinking my code was pretty lame and no one would use it. With KUZU already dominating the space, why would anyone accept mine? I guess wey-gu’s encouragement really helped—Nebulagraph’s clients are all big names, haha. Suddenly, donating to this larger community platform feels like it’ll have a brighter future!
Just remembered something awkward: every time I chat with wey-gu, I insist on using “您” (formal ‘you’). I guess that’s my “typical respect for elders” from institutional education and traditional culture. Then he called me out—“Don’t use ‘您’.” Suddenly realized how distant that felt. Wey-gu actually prefers equal exchanges. This reminded me of something iyear once mentioned: within the community, your identity and status matter least. Regardless of position, age, or nationality, everyone engages in equal dialogue.
That’s ALL! Though I’m not sure if I’ve finished writing, I’m already sleepy haha
2025-08-18 03:58AM
Translated on October 24, 2025 (Happy birthday to myself!)